在 上一篇 中,我們學會了如何讀取並操作影像矩陣。但要讓電腦真正「看懂」圖片裡是什麼,我們就需要請出深度學習的主角:卷積神經網路 (CNN, Convolutional Neural Network)。
這篇文章將透過經典的 MNIST 手寫數字資料集,紀錄訓練出人生第一個影像辨識模型的完整流程。
一、資料前處理:把圖片變成神經網路喜歡的樣子
在把圖片餵給 PyTorch 模型之前,我們需要使用 transforms 進行兩項關鍵轉換:
ToTensor():- 在 Part 1 我們提過,一般圖片的像素值是 0 到 255 的整數 (
uint8)。但神經網路更喜歡處理「小數」。這個指令會自動將圖片轉換為 PyTorch 的張量 (Tensor),並把數值壓縮到 0.0 到 1.0 之間。 - 順帶一提,PyTorch 的通道順序跟別人不一樣,它會把 H $\times$ W $\times$ C 轉換成 C $\times$ H $\times$ W。
- 在 Part 1 我們提過,一般圖片的像素值是 0 到 255 的整數 (
Normalize():- 將數值進一步依照資料集的平均值與標準差進行平移與縮放,讓資料分佈更均勻,這能幫助模型在訓練時更快收斂 。
二、CNN 模型架構:特徵提取與分類
在這支程式中,我們定義了一個名為 SimpleCNN 的網路,它可以分為兩大部門:
- 卷積層 (Conv Block) ─ 負責「找特徵」:
利用
nn.Conv2d在圖片上掃描,尋找邊緣、線條或特定的形狀。接著透過nn.MaxPool2d(池化層) 將圖片「縮小」(例如從 28x28 變成 14x14)。這樣不僅能保留最重要的特徵,還能大幅減少運算量。 - 分類層 (Classifier) ─ 負責「下結論」:
經過卷積層提取後,我們會得到高維度的特徵圖。這時必須用
nn.Flatten()將它「攤平」成一維陣列,最後交給全連接層 (nn.Linear) 來投票,決定這張圖片到底是 0 到 9 中的哪一個數字。
三、神經網路的修練:訓練迴圈
深度學習的訓練,其實就是不斷重複以下四個神聖的步驟:
- Forward:
outputs = model(images)讓模型猜猜看這批圖片是什麼數字。 - Loss:
loss = criterion(outputs, labels)拿模型的預測結果跟「標準答案」比對,計算出誤差值有多大(使用 CrossEntropyLoss)。 - Backward:
loss.backward()利用微積分的連鎖律,計算出模型裡每一個參數「該為這個誤差負多少責任」(也就是計算梯度)。 - Update:
optimizer.step()根據剛剛算出的責任歸屬,稍微調整模型內的參數,讓它下一次猜得更準。
(註:每次更新前,必須記得使用 optimizer.zero_grad() 把上一次的梯度清空!)
四、成果展示與評估
經過 5 個 Epoch (訓練週期) 的努力,我們可以透過訓練曲線來檢視模型的健康狀況:
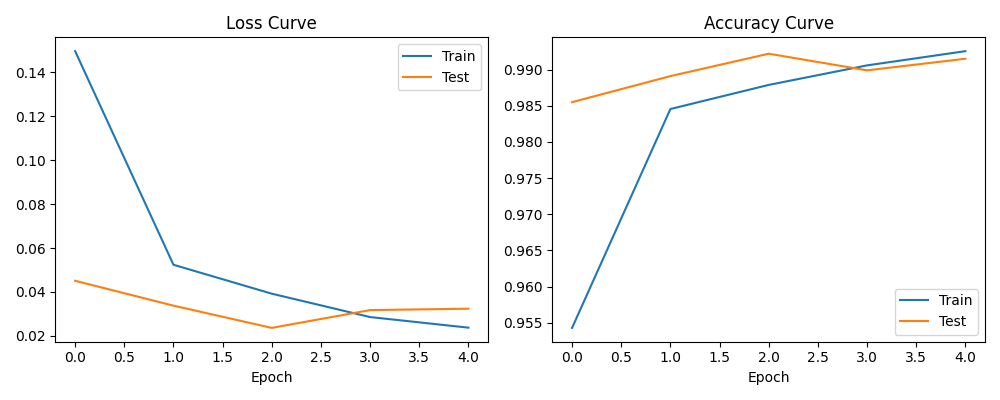
- Loss Curve:可以看到 Train Loss 與 Test Loss 都順利往下降,代表模型確實有在學習,且沒有嚴重的 Overfitting。
- Accuracy Curve:準確率穩步上升,最終在測試集上達到了非常高的準確率(通常 MNIST 都能輕鬆達到 98% 以上)。
最後,讓我們把測試集抽幾張出來,看看模型的實際預測結果:

看到這些手寫的扭曲數字都被標上綠色的正確預測 (Green=O),真的非常有成就感!這就是我們從零訓練出的第一個 AI 視覺模型。
相關實作程式碼請參閱 Github:Example 2