在 上一篇 中,我們用 MNIST 手寫數字資料集訓練了第一個 CNN 模型,準確率輕鬆突破 98%。但現實世界的圖片可沒那麼簡單——這篇文章將挑戰更困難的 CIFAR-10 彩色影像資料集,並引入幾個讓模型更強、更穩健的新技巧。
一、CIFAR-10:比 MNIST 難在哪裡?
MNIST 是 28×28 的灰階圖,只要辨識 0 到 9 的數字;CIFAR-10 則是 32×32 的彩色圖,要辨識 10 種截然不同的類別:
airplane,automobile,bird,cat,deer,dog,frog,horse,ship,truck
彩色圖帶來的第一個變化,就是通道數從 1 變成 3(RGB 三個色板)。這意味著輸入資料的第一個維度從 1 × H × W 變成 3 × H × W,模型的第一層卷積也必須從 Conv2d(1, ...) 改為 Conv2d(3, ...)。
更根本的挑戰在於:貓跟狗長相相似、鳥跟飛機都有翅膀——視覺上的歧義讓分類難度大幅提升,光靠簡單的網路很容易過擬合。
二、資料增強:讓模型見多識廣
對付過擬合的第一招,是在訓練集上加入隨機的資料增強 (Data Augmentation)。增強的核心思想很直覺:同一張圖片,從不同角度、不同光線看,應該都要被辨識正確。
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 50% 機率水平翻轉
transforms.RandomCrop(32, padding=4), # 先補邊再隨機裁切
transforms.ColorJitter(brightness=0.2, # 隨機調整亮度 ±20%
contrast=0.2), # 隨機調整對比 ±20%
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465),
(0.2023, 0.1994, 0.2010)),
])
重點是:測試集絕對不能做隨機增強,只做標準化。這樣才能確保評估結果的一致性與公平性。
這裡 Normalize 使用的平均值與標準差是 CIFAR-10 資料集的統計值,與 Part 2 中 MNIST 的數值不同,這是因為兩個資料集的像素分佈本來就不一樣。
三、更深的 CNN:Double Conv Block
為了應付更複雜的彩色圖,我們設計了一個更深的 DeepCNN。這次的 Conv Block 變成了兩層卷積,並在每層後面加上 BatchNorm(批次正規化):
def conv_block(in_ch, out_ch):
return nn.Sequential(
nn.Conv2d(in_ch, out_ch, 3, padding=1, bias=False),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
nn.Conv2d(out_ch, out_ch, 3, padding=1, bias=False),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
nn.MaxPool2d(2),
)
整個 features 由三個這樣的 Block 堆疊而成,通道數依序加深,空間尺寸依序縮小:
| Block | 輸入通道 → 輸出通道 | 空間尺寸 |
|---|---|---|
| Block 1 | 3 → 64 | 32×32 → 16×16 |
| Block 2 | 64 → 128 | 16×16 → 8×8 |
| Block 3 | 128 → 256 | 8×8 → 4×4 |
為什麼需要 BatchNorm?
BatchNorm 解決了深層網路訓練時一個很頭痛的問題——內部共變數偏移 (Internal Covariate Shift)。簡單說,隨著參數更新,每一層的輸入分佈會一直在變動,讓後面的層很難穩定學習。BatchNorm 在每個 mini-batch 上,將該層的輸出重新拉回均值為 0、方差為 1 的分佈(再透過可學習的 γ、β 還原彈性),效果是:
- 訓練更穩定、收斂更快
- 對學習率的選擇較不敏感
- 本身也有一定的正規化效果
因為 BatchNorm 自帶偏置的效果,後面的 Conv2d 就不需要多餘的 bias,所以設定 bias=False。
Dropout:讓分類器不要太依賴特定神經元
進到分類層之前,我們加入 Dropout(0.5),讓 50% 的神經元在每次訓練時被隨機「關掉」:
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(256 * 4 * 4, 512),
nn.ReLU(inplace=True),
nn.Dropout(0.5), # 訓練時隨機丟棄 50%
nn.Linear(512, 10),
)
這迫使模型不能只靠幾個特定神經元做判斷,而是學會更分散、更泛化的表示。Dropout 只在訓練時啟動,評估模式(model.eval())下會自動關閉。
四、更聰明的優化策略
AdamW 取代 Adam
這次使用的 AdamW 是 Adam 的改良版。兩者差別在於權重衰減 (Weight Decay) 的處理方式:
- Adam +
weight_decay:權重衰減被混進梯度更新,與自適應學習率交互影響,效果打折。 - AdamW:權重衰減獨立於梯度之外直接作用在參數上,是更純粹的 L2 正規化。
optimizer = optim.AdamW(model.parameters(), lr=0.001, weight_decay=1e-4)
CosineAnnealingLR:讓學習率優雅地下降
固定學習率容易讓模型在後期收斂到不夠好的位置。CosineAnnealingLR 讓學習率依照餘弦函數的曲線,從初始值平滑地衰減到接近 0:
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=EPOCHS)
這比突然「階梯式」降低學習率更為平順,尤其在訓練後期能讓模型微幅調整,落到更好的局部最優解。
五、混淆矩陣:不只看總準確率
整體準確率只告訴你「平均答對幾題」,卻掩蓋了「哪幾類特別難分」。混淆矩陣 (Confusion Matrix) 是解決這個問題的利器,它把每個類別的預測結果完整呈現成一張表格:
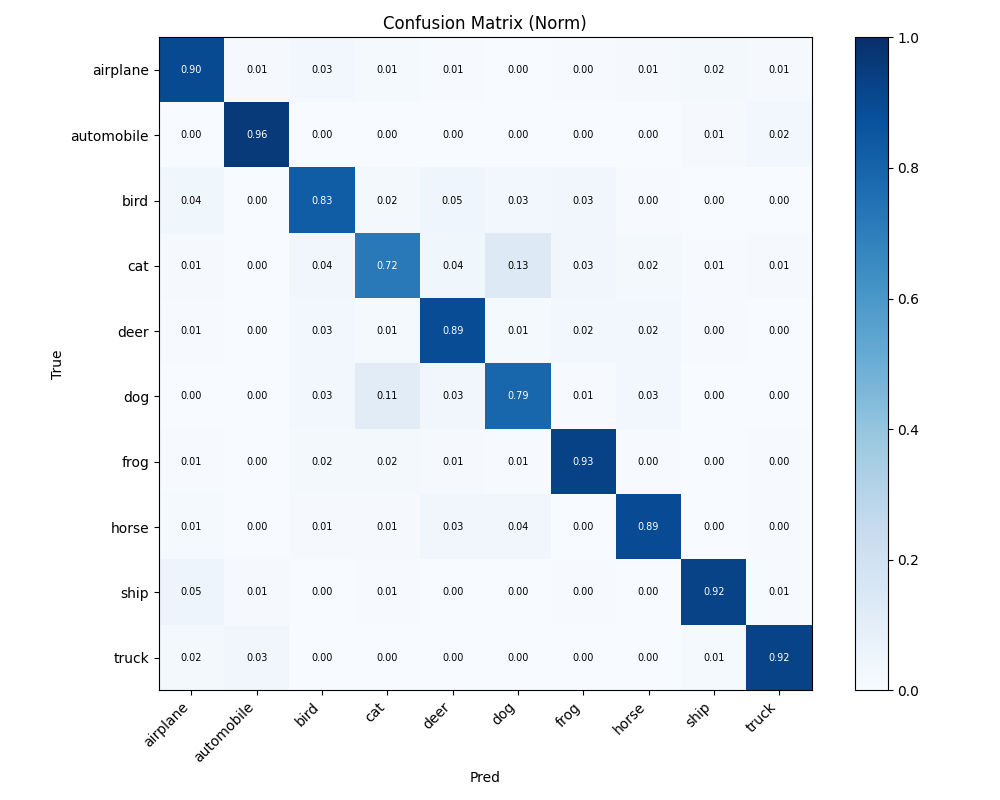
從這張正規化的混淆矩陣(每列加總為 1.0)可以觀察到幾個有趣的現象:
- automobile(96%)、frog(93%) 是最容易辨識的類別,外型特徵非常明顯。
- cat(72%) 是最難的類別——有 13% 的貓被誤認成狗,還有 4% 被當成鳥。
- cat vs. dog(貓狗互相混淆)是最典型的錯誤:模型顯然覺得這兩者長很像,這其實跟人類的直覺完全一致!
- bird vs. airplane:有 4% 的鳥被認成飛機,背景(天空)確實可能造成混淆。
六、成果展示
訓練 15 個 Epoch 後,來看看模型的學習曲線:
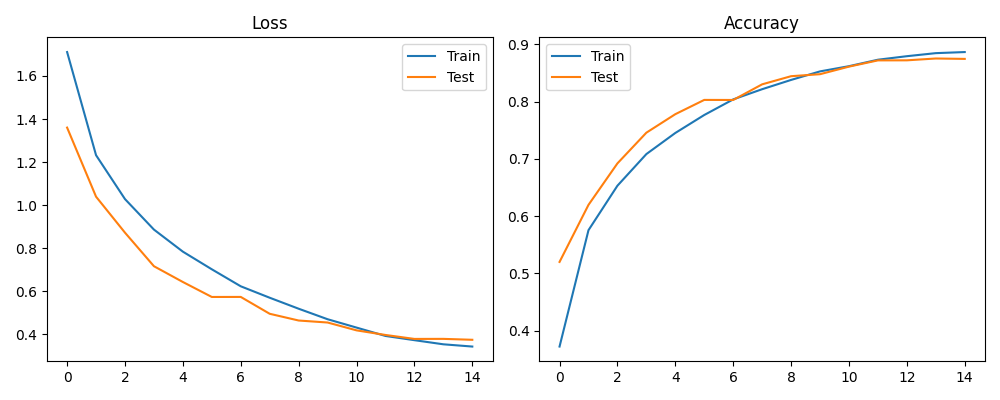
- Loss Curve:Train Loss 與 Test Loss 幾乎同步下降,最終都收斂到約 0.37,兩者之間幾乎沒有落差,表示模型沒有發生過擬合。
- Accuracy Curve:測試集準確率穩步爬升,最終約落在 87% 左右。對比 MNIST 的 98%+,這個數字看似不高,但考量到 CIFAR-10 視覺上的歧義性,這已經是相當不錯的成果。
這次從頭到尾學到的技巧,可以整理成下面這張「對抗過擬合」的清單:
| 技巧 | 作用位置 | 解決的問題 |
|---|---|---|
| Data Augmentation | 資料層 | 增加訓練樣本多樣性 |
| BatchNorm | 網路中間 | 穩定訓練、加速收斂 |
| Dropout | 分類器 | 避免過度依賴特定神經元 |
| AdamW + weight_decay | 優化器 | 純粹的 L2 正規化 |
| CosineAnnealingLR | 排程器 | 後期精細調整、更好收斂 |
相關實作程式碼請參閱 Github:Example 3